
Apache Knox gateway is a specialized reverse proxy gateway for various Hadoop REST APIs. However, the gateway is built entirely upon a fairly generic framework. This framework is used to “plug-in” all of the behavior that makes it specific to Hadoop in general and any particular Hadoop REST API. It would be equally as possible to create a customized reverse proxy for other non-Hadoop HTTP endpoints. This approach is taken to ensure that the Apache Knox gateway can scale with the rapidly evolving Hadoop ecosystem.
Throughout this guide we will be using a publicly available REST API to demonstrate the development of various extension mechanisms. http://openweathermap.org/
The gateway itself is a layer over an embedded Jetty JEE server. At the very highest level the gateway processes requests by using request URLs to lookup specific JEE Servlet Filter chain that is used to process the request. The gateway framework provides extensible mechanisms to assemble chains of custom filters that support secured access to services.
The gateway has two primary extensibility mechanisms: Service and Provider. The Service extensibility framework provides a way to add support for new HTTP/REST endpoints. For example, the support for WebHdfs is plugged into the Knox gateway as a Service. The Provider extensibility framework allows adding new features to the gateway that can be used across Services. An example of a Provider is an authentication provider. Providers can also expose APIs that other service and provider extensions can utilize.
Service and Provider integrations interact with the gateway framework in two distinct phases: Deployment and Runtime. The gateway framework can be thought of as a layer over the JEE Servlet framework. Specifically all runtime processing within the gateway is performed by JEE Servlet Filters. The two phases interact with this JEE Servlet Filter based model in very different ways. The first phase, Deployment, is responsible for converting fairly simple to understand configuration called topology into JEE WebArchive (WAR) based implementation details. The second phase, Runtime, is the processing of requests via a set of Filters configured in the WAR.
From an “ethos” perspective, Service and Provider extensions should attempt to incur complexity associated with configuration in the deployment phase. This should allow for very streamlined request processing that is very high performance and easily testable. The preference at runtime, in OO style, is for small classes that perform a specific function. The ideal set of implementation classes are then assembled by the Service and Provider plugins during deployment.
A second critical design consideration is streaming. The processing infrastructure is build around JEE Servlet Filters as they provide a natural streaming interception model. All Provider implementations should make every attempt to maintaining this streaming characteristic.
The table below describes the purpose of the current modules in the project. Of particular importance are the root pom.xml and the gateway-release module. The root pom.xml is critical because this is where all dependency version must be declared. There should be no dependency version information in module pom.xml files. The gateway-release module is critical because the dependencies declared there essentially define the classpath of the released gateway server. This is also true of the other -release modules in the project.
| File/Module | Description |
|---|---|
| LICENSE | The license for all source files in the release. |
| NOTICE | Attributions required by dependencies. |
| README | A brief overview of the Knox project. |
| CHANGES | A description of the changes for each release. |
| ISSUES | The knox issues for the current release. |
| gateway-util-common | Common low level utilities used by many modules. |
| gateway-util-launcher | The launcher framework. |
| gateway-util-urltemplate | The i18n logging and resource framework. |
| gateway-i18n | The URL template and rewrite utilities |
| gateway-i18n-logging-log4j | The integration of i18n logging with log4j. |
| gateway-i18n-logging-sl4j | The integration of i18n logging with sl4j. |
| gateway-spi | The SPI for service and provider extensions. |
| gateway-provider-identity-assertion-common | The identity assertion provider base |
| gateway-provider-identity-assertion-concat | An identity assertion provider that facilitates prefix and suffix concatenation. |
| gateway-provider-identity-assertion-pseudo | The default identity assertion provider. |
| gateway-provider-jersey | The jersey display provider. |
| gateway-provider-rewrite | The URL rewrite provider. |
| gateway-provider-rewrite-func-hostmap-static | Host mapping function extension to rewrite. |
| gateway-provider-rewrite-func-service-registry | Service registry function extension to rewrite. |
| gateway-provider-rewrite-step-secure-query | Crypto step extension to rewrite. |
| gateway-provider-security-authz-acls | Service level authorization. |
| gateway-provider-security-jwt | JSON Web Token utilities. |
| gateway-provider-security-preauth | Preauthenticated SSO header support. |
| gateway-provider-security-shiro | Shiro authentiation integration. |
| gateway-provider-security-webappsec | Filters to prevent common webapp security issues. |
| gateway-service-as | The implementation of the Access service POC. |
| gateway-service-definitions | The implementation of the Service definition and rewrite files. |
| gateway-service-hbase | The implementation of the HBase service. |
| gateway-service-hive | The implementation of the Hive service. |
| gateway-service-oozie | The implementation of the Oozie service. |
| gateway-service-tgs | The implementation of the Ticket Granting service POC. |
| gateway-service-webhdfs | The implementation of the WebHdfs service. |
| gateway-server | The implementation of the Knox gateway server. |
| gateway-shell | The implementation of the Knox Groovy shell. |
| gateway-test-ldap | Pulls in all of the dependencies of the test LDAP server. |
| gateway-server-launcher | The launcher definition for the gateway. |
| gateway-shell-launcher | The launcher definition for the shell. |
| knox-cli-launcher | A module to pull in all of the dependencies of the CLI. |
| gateway-test-ldap-launcher | The launcher definition for the test LDAP server. |
| gateway-release | The definition of the gateway binary release. Contains content and dependencies to be included in binary gateway package. |
| gateway-test-utils | Various utilities used in unit and system tests. |
| gateway-test | The functional tests. |
| pom.xml | The top level pom. |
| build.xml | A collection of utility for building and releasing. |
The project uses Maven in general with a few convenience Ant targets.
Building the project can be built via Maven or Ant. The two commands below are equivalent.
mvn clean install
ant
A more complete build can be done that builds and generates the unsigned ZIP release artifacts. You will find these in the target/{version} directory (e.g. target/0.XX.0-SNAPSHOT).
mvn -Prelease clean install
ant release
There are a few other Ant targets that are especially convenient for testing.
This command installs the gateway into the {{{install}}} directory of the project. Note that this command does not first build the project.
ant install-test-home
This command starts the gateway and LDAP servers installed by the command above into a test GATEWAY_HOME (i.e. install). Note that this command does not first install the test home.
ant start-test-servers
So putting things together the following Ant command will build a release, install it and start the servers ready for manual testing.
ant release install-test-home start-test-servers
There are two distinct phases in the behavior of the gateway. These are the deployment and runtime phases. The deployment phase is responsible for converting topology descriptors into an executable JEE style WAR. The runtime phase is the processing of requests via WAR created during the deployment phase.
The deployment phase is arguably the more complex of the two phases. This is because runtime relies on well known JEE constructs while deployment introduces new framework concepts. The base concept of the deployment framework is that of a “contributor”. In the framework, contributors are pluggable component responsible for generating JEE WAR artifacts from topology files.
The goal of the deployment phase is to take easy to understand topology descriptions and convert them into optimized runtime artifacts. Our goal is not only should the topology descriptors be easy to understand, but have them be easy for a management system (e.g. Ambari) to generate. Think of deployment as compiling an assembly descriptor into a JEE WAR. WARs are then deployed to an embedded JEE container (i.e. Jetty).
Consider the results of starting the gateway the first time. There are two sets of files that are relevant for deployment. The first is the topology file <GATEWAY_HOME>/conf/topologies/sandbox.xml. This second set is the WAR structure created during the deployment of the topology file.
data/deployments/sandbox.war.143bfef07f0/WEB-INF
web.xml
gateway.xml
shiro.ini
rewrite.xml
hostmap.txt
Notice that the directory sandbox.war.143bfef07f0 is an “unzipped” representation of a JEE WAR file. This specifically means that it contains a WEB-INF directory which contains a web.xml file. For the curious the strange number (i.e. 143bfef07f0) in the name of the WAR directory is an encoded timestamp. This is the timestamp of the topology file (i.e. sandbox.xml) at the time the deployment occurred. This value is used to determine when topology files have changed and redeployment is required.
Here is a brief overview of the purpose of each file in the WAR structure.
The deployment framework follows “visitor” style patterns. Each topology file is parsed and the various constructs within it are “visited”. The appropriate contributor for each visited construct is selected by the framework. The contributor is then passed the contrust from the topology file and asked to update the JEE WAR artifacts. Each contributor is free to inspect and modify any portion of the WAR artifacts.
The diagram below provides an overview of the deployment processing. Detailed descriptions of each step follow the diagram.
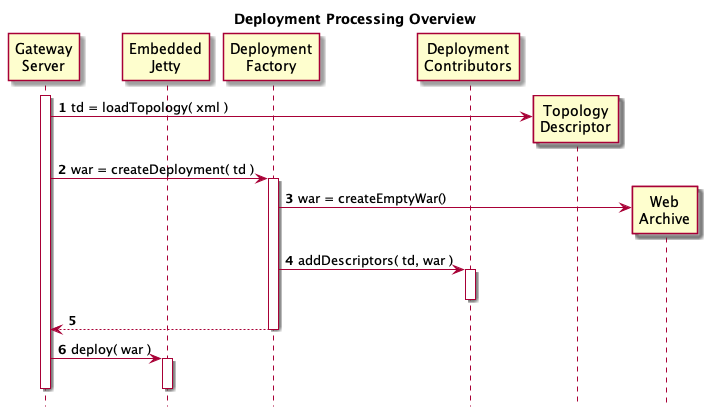
The gateway server loads a topology file from conf/topologies into an internal structure.
The gateway server delegates to a deployment factory to create the JEE WAR structure.
The deployment factory first creates a basic WAR structure with WEB-INF/web.xml.
Each provider and service in the topology is visited and the appropriate deployment contributor invoked. Each contributor is passed the appropriate information from the topology and modifies the WAR structure.
A complete WAR structure is returned to the gateway service.
The gateway server uses internal container APIs to dynamically deploy the WAR.
The Java method below is the actual code from the DeploymentFactory that implements this behavior. You will note the initialize, contribute, finalize sequence. Each contributor is given three opportunities to interact with the topology and archive. This allows the various contributors to interact if required. For example, the service contributors use the deployment descriptor added to the WAR by the rewrite provider.
public static WebArchive createDeployment( GatewayConfig config, Topology topology ) {
Map<String,List<ProviderDeploymentContributor>> providers;
Map<String,List<ServiceDeploymentContributor>> services;
DeploymentContext context;
providers = selectContextProviders( topology );
services = selectContextServices( topology );
context = createDeploymentContext( config, topology.getName(), topology, providers, services );
initialize( context, providers, services );
contribute( context, providers, services );
finalize( context, providers, services );
return context.getWebArchive();
}
Below is a diagram that provides more detail. This diagram focuses on the interactions between the deployment factory and the service deployment contributors. Detailed description of each step follow the diagram.
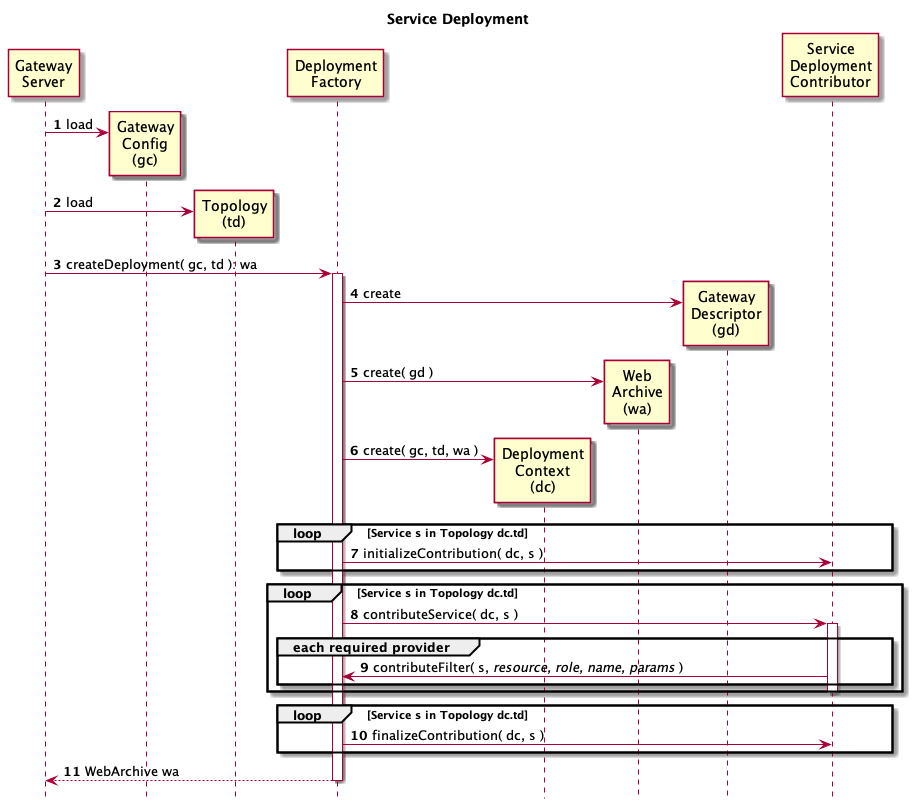
The gateway server loads global configuration (i.e.
The gateway server loads a topology descriptor file.
The gateway server delegates to the deployment factory to create a deployable WAR structure.
The deployment factory creates a runtime descriptor to configure that gateway servlet.
The deployment factory creates a basic WAR structure and adds the gateway servlet runtime descriptor to it.
The deployment factory creates a deployment context object and adds the WAR structure to it.
For each service defined in the topology descriptor file the appropriate service deployment contributor is selected and invoked. The correct service deployment contributor is determined by matching the role of a service in the topology descriptor to a value provided by the getRole() method of the ServiceDeploymentContributor interface. The initializeContribution method from each service identified in the topology is called. Each service deployment contributor is expected to setup any runtime artifacts in the WAR that other services or provides may need.
The contributeService method from each service identified in the topology is called. This is where the service deployment contributors will modify any runtime descriptors.
One of they ways that a service deployment contributor can modify the runtime descriptors is by asking the framework to contribute filters. This is how services are loosely coupled to the providers of features. For example a service deployment contributor might ask the framework to contribute the filters required for authorization. The deployment framework will then delegate to the correct provider deployment contributor to add filters for that feature.
Finally the finalizeContribution method for each service is invoked. This provides an opportunity to react to anything done via the contributeService invocations and tie up any loose ends.
The populated WAR is returned to the gateway server.
The following diagram will provided expanded detail on the behavior of provider deployment contributors. Much of the beginning and end of the sequence shown overlaps with the service deployment sequence above. Those steps (i.e. 1-6, 17) will not be described below for brevity. The remaining steps have detailed descriptions following the diagram.
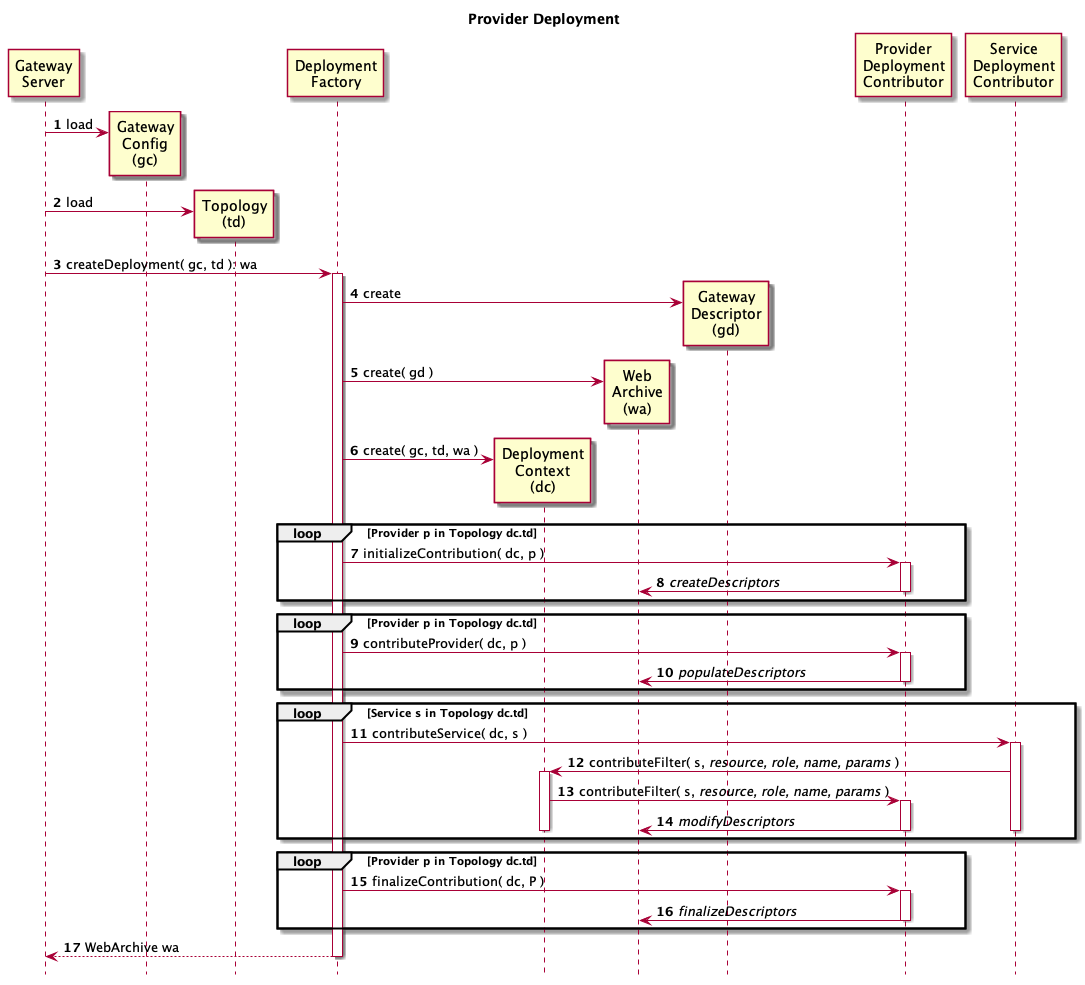
For each provider the appropriate provider deployment contributor is selected and invoked. The correct service deployment contributor is determined by first matching the role of a provider in the topology descriptor to a value provided by the getRole() method of the ProviderDeploymentContributor interface. If this is ambiguous, the name from the topology is used match the value provided by the getName() method of the ProviderDeploymentContributor interface. The initializeContribution method from each provider identified in the topology is called. Each provider deployment contributor is expected to setup any runtime artifacts in the WAR that other services or provides may need. Note: In addition, others provider not explicitly referenced in the topology may have their initializeContribution method called. If this is the case only one default instance for each role declared vis the getRole() method will be used. The method used to determine the default instance is non-deterministic so it is best to select a particular named instance of a provider for each role.
Each provider deployment contributor will typically add any runtime deployment descriptors it requires for operation. These descriptors are added to the WAR structure within the deployment context.
The contributeProvider method of each configured or default provider deployment contributor is invoked.
Each provider deployment contributor populates any runtime deployment descriptors based on information in the topology.
Provider deployment contributors are never asked to contribute to the deployment directly. Instead a service deployment contributor will ask to have a particular provider role (e.g. authentication) contribute to the deployment.
A service deployment contributor asks the framework to contribute filters for a given provider role.
The framework selects the appropriate provider deployment contributor and invokes its contributeFilter method.
During this invocation the provider deployment contributor populate populate service specific information. In particular it will add filters to the gateway servlet’s runtime descriptor by adding JEE Servlet Filters. These filters will be added to the resources (or URLs) identified by the service deployment contributor.
The finalizeContribute method of all referenced and default provider deployment contributors is invoked.
The provider deployment contributor is expected to perform any final modifications to the runtime descriptors in the WAR structure.
The runtime behavior of the gateway is somewhat simpler as it more or less follows well known JEE models. There is one significant wrinkle. The filter chains are managed within the GatewayServlet as opposed to being managed by the JEE container. This is the result of an early decision made in the project. The intention is to allow more powerful URL matching than is provided by the JEE Servlet mapping mechanisms.
The diagram below provides a high level overview of the runtime processing. An explanation for each step is provided after the diagram.
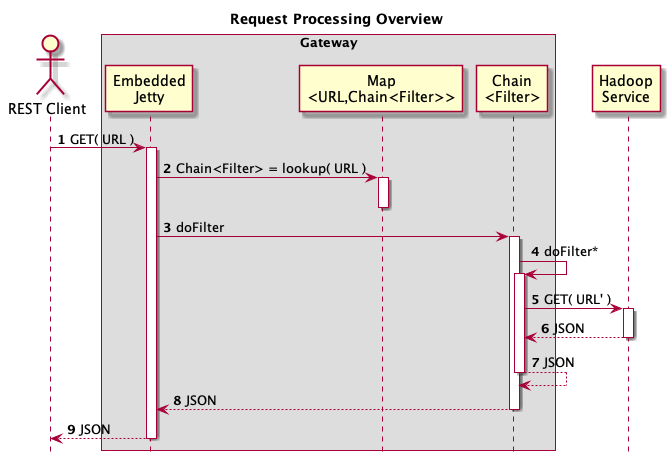
A REST client makes a HTTP request that is received by the embedded JEE container.
A filter chain is looked up in a map of URLs to filter chains.
The filter chain, which is itself a filter, is invoked.
Each filter invokes the filters that follow it in the chain. The request and response objects can be wrapped in typically JEE Filter fashion. Filters may not continue chain processing and return if that is appropriate.
Eventually the end of the last filter in the chain is invoked. Typically this is a special “dispatch” filter that is responsible for dispatching the request to the ultimate endpoint. Dispatch filters are also responsible for reading the response.
The response may be in the form of a number of content types (e.g. application/json, text/xml).
The response entity is streamed through the various response wrappers added by the filters. These response wrappers may rewrite various portions of the headers and body as per their configuration.
The return of the response entity to the client is ultimately “pulled through” the filter response wrapper by the container.
The response entity is returned original client.
This diagram providers a more detailed breakdown of the request processing. Again descriptions of each step follow the diagram.
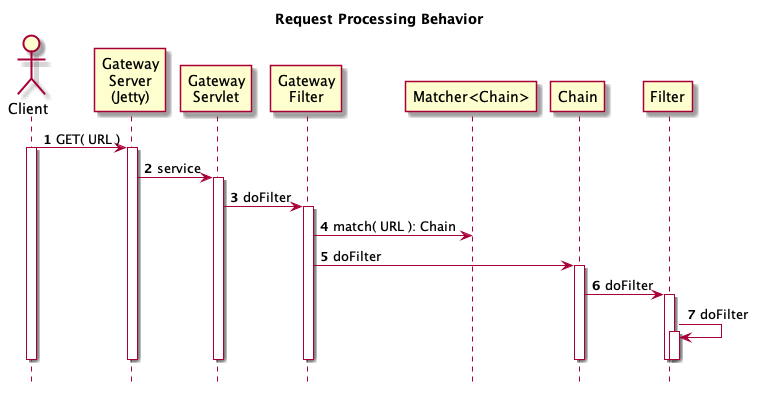
A REST client makes a HTTP request that is received by the embedded JEE container.
The embedded container looks up the servlet mapped to the URL and invokes the service method. This our case the GatewayServlet is mapped to /* and therefore receives all requests for a given topology. Keep in mind that the WAR itself is deployed on a root context path that typically contains a level for the gateway and the name of the topology. This means that there is a single GatewayServlet per topology and it is effectivly mapped to
The GatewayServlet holds a single reference to a GatewayFilter which is a specialized JEE Servlet Filter. This choice was made to allow the GatewayServlet to dynamically deploy modified topologies. This is done by building a new GatewayFilter instance and replacing the old in an atomic fashion.
The GatewayFilter contains another layer of URL mapping as defined in the gateway.xml runtime descriptor. The various service deployment contributor added these mappings at deployment time. Each service may add a number of different sub-URLs depending in their requirements. These sub-URLs will all be mapped to independently configured filter chains.
The GatewayFilter invokes the doFilter method on the selected chain.
The chain invokes the doFilter method of the first filter in the chain.
Each filter in the chain continues processing by invoking the doFilter on the next filter in the chain. Ultimately a dispatch filter forward the request to the real service instead of invoking another filter. This is sometimes referred to as pivoting.
TODO
<web-app>
<servlet>
<servlet-name>sample</servlet-name>
<servlet-class>org.apache.hadoop.gateway.GatewayServlet</servlet-class>
<init-param>
<param-name>gatewayDescriptorLocation</param-name>
<param-value>gateway.xml</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>sandbox</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>
<listener>
<listener-class>org.apache.hadoop.gateway.services.GatewayServicesContextListener</listener-class>
</listener>
...
</web-app>
<gateway>
<resource>
<role>WEATHER</role>
<pattern>/weather/**?**</pattern>
<filter>
<role>authentication</role>
<name>sample</name>
<class>...</class>
</filter>
<filter>...</filter>*
</resource>
</gateway>
@Test
public void testDevGuideSample() throws Exception {
Template pattern, input;
Matcher<String> matcher;
Matcher<String>.Match match;
// GET http://api.openweathermap.org/data/2.5/weather?q=Palo+Alto
pattern = Parser.parse( "/weather/**?**" );
input = Parser.parse( "/weather/2.5?q=Palo+Alto" );
matcher = new Matcher<String>();
matcher.add( pattern, "fake-chain" );
match = matcher.match( input );
assertThat( match.getValue(), is( "fake-chain") );
}
There are a number of extension points available in the gateway: services, providers, rewrite steps and functions, etc. All of these use the Java ServiceLoader mechanism for their discovery. There are two ways to make these extensions available on the class path at runtime. The first way to add a new module to the project and have the extension “built-in”. The second is to add the extension to the class path of the server after it is installed. Both mechanism are described in more detail below.
Extensions are discovered via Java’s [Service Loader|http://docs.oracle.com/javase/6/docs/api/java/util/ServiceLoader.html] mechanism. There are good [tutorials|http://docs.oracle.com/javase/tutorial/ext/basics/spi.html] available for learning more about this. The basics come town to two things.
Implement the service contract interface (e.g. ServiceDeploymentContributor, ProviderDeploymentContributor)
Create a file in META-INF/services of the JAR that will contain the extension. This file will be named as the fully qualified name of the contract interface (e.g. org.apache.hadoop.gateway.deploy.ProviderDeploymentContributor). The contents of the file will be the fully qualified names of any implementation of that contract interface in that JAR.
One tip is to include a simple test with each of you extension to ensure that it will be properly discovered. This is very helpful in situations where a refactoring fails to change the a class in the META-INF/services files. An example of one such test from the project is shown below.
@Test
public void testServiceLoader() throws Exception {
ServiceLoader loader = ServiceLoader.load( ProviderDeploymentContributor.class );
Iterator iterator = loader.iterator();
assertThat( "Service iterator empty.", iterator.hasNext() );
while( iterator.hasNext() ) {
Object object = iterator.next();
if( object instanceof ShiroDeploymentContributor ) {
return;
}
}
fail( "Failed to find " + ShiroDeploymentContributor.class.getName() + " via service loader." );
}
One way to extend the functionality of the server without having to recompile is to add the extension JARs to the servers class path. As an extensible server this is made straight forward but it requires some understanding of how the server’s classpath is setup. In the
The bin directory contains very small “launcher” jars that contain only enough code to read configuration and setup a class path. By default the configuration of a launcher is embedded with the launcher JAR but it may also be extracted into a .cfg file. In that file you will see how the class path is defined.
class.path=../lib/*.jar,../dep/*.jar;../ext;../ext/*.jar
The paths are all relative to the directory that contains the launcher JAR.
Note that order is significant. The lib JARs take precedence over dep JARs and they take precedence over ext classes and JARs.
Integrating an extension into the project follows well established Maven patterns for adding modules. Below are several points that are somewhat unique to the Knox project.
Add the module to the root pom.xml file’s
Any new dependencies must be represented in the root pom.xml file’s
If the extension is to be “built into” the released gateway server it needs to be added as a dependency to the gateway-release module. This is done by adding to the
More detailed examples of adding both a service and a provider extension are provided in subsequent sections.
Services are extensions that are responsible for converting information in the topology file to runtime descriptors. Typically services do not require their own runtime descriptors. Rather, they modify either the gateway runtime descriptor (i.e. gateway.xml) or descriptors of other providers (e.g. rewrite.xml).
The service provider interface for a Service is ServiceDeploymentContributor and is shown below.
package org.apache.hadoop.gateway.deploy;
import org.apache.hadoop.gateway.topology.Service;
public interface ServiceDeploymentContributor {
String getRole();
void initializeContribution( DeploymentContext context );
void contributeService( DeploymentContext context, Service service ) throws Exception;
void finalizeContribution( DeploymentContext context );
}
Each service provides an implementation of this interface that is discovered via the ServerLoader mechanism previously described. The meaning of this is best understood in the context of the structure of the topology file. A fragment of a topology file is shown below.
<topology>
<gateway>
....
</gateway>
<service>
<role>WEATHER</role>
<url>http://api.openweathermap.org/data</url>
</service>
....
</topology>
With these two things a more detailed description of the purpose of each ServiceDeploymentContributor method should be helpful.
<service><role> with a particular ServiceDeploymentContributor implementation. See below how the example WeatherDeploymentContributor implementation returns the role WEATHER that matches the value in the topology file. This will result in the WeatherDeploymentContributor’s methods being invoked when a WEATHER service is encountered in the topology file.public class WeatherDeploymentContributor extends ServiceDeploymentContributorBase {
private static final String ROLE = "WEATHER";
@Override
public String getRole() {
return ROLE;
}
...
}
In order to understand the job of the ServiceDeploymentContributor a few runtime descriptors need to be introduced.
<gateway>
<resource>
<role>WEATHER</role>
<pattern>/weather/**?**</pattern>
<filter>
<role>authentication</role>
<name>sample</name>
<class>...</class>
</filter>
<filter>...</filter>*
...
</resource>
</gateway>
<rules>
<rule dir="IN" name="WEATHER/openweathermap/inbound/versioned/file"
pattern="*://*:*/**/weather/{version}?{**}">
<rewrite template="{$serviceUrl[WEATHER]}/{version}/weather?{**}"/>
</rule>
</rules>
With these two descriptors in mind a detailed breakdown of the WeatherDeploymentContributor’s contributeService method will make more sense. At a high level the important concept is that contributeService is invoked by the framework for each
public class WeatherDeploymentContributor extends ServiceDeploymentContributorBase {
...
@Override
public void contributeService( DeploymentContext context, Service service ) throws Exception {
contributeResources( context, service );
contributeRewriteRules( context );
}
private void contributeResources( DeploymentContext context, Service service ) throws URISyntaxException {
ResourceDescriptor resource = context.getGatewayDescriptor().addResource();
resource.role( service.getRole() );
resource.pattern( "/weather/**?**" );
addAuthenticationFilter( context, service, resource );
addRewriteFilter( context, service, resource );
addDispatchFilter( context, service, resource );
}
private void contributeRewriteRules( DeploymentContext context ) throws IOException {
UrlRewriteRulesDescriptor allRules = context.getDescriptor( "rewrite" );
UrlRewriteRulesDescriptor newRules = loadRulesFromClassPath();
allRules.addRules( newRules );
}
...
}
The DeploymentContext parameter contains information about the deployment as well as the WAR structure being created via deployment. The Service parameter is the object representation of the
protected void addRewriteFilter( DeploymentContext context, Service service, ResourceDescriptor resource ) {
context.contributeFilter( service, resource, "rewrite", null, null );
}
<project>
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.apache.hadoop</groupId>
<artifactId>gateway</artifactId>
<version>0.12.0-SNAPSHOT</version>
</parent>
<artifactId>gateway-service-weather</artifactId>
<name>gateway-service-weather</name>
<description>A sample extension to the gateway for a weather REST API.</description>
<licenses>
<license>
<name>The Apache Software License, Version 2.0</name>
<url>https://www.apache.org/licenses/LICENSE-2.0.txt</url>
<distribution>repo</distribution>
</license>
</licenses>
<dependencies>
<dependency>
<groupId>${gateway-group}</groupId>
<artifactId>gateway-spi</artifactId>
</dependency>
<dependency>
<groupId>${gateway-group}</groupId>
<artifactId>gateway-provider-rewrite</artifactId>
</dependency>
... Test Dependencies ...
</dependencies>
</project>
As of release 0.6.0, the gateway now also supports a declarative way of plugging-in a new Service. A Service can be defined with a combination of two files, these are:
service.xml
rewrite.xml
The rewrite.xml file contains the rewrite rules as defined in other sections of this guide, and the service.xml file contains the various routes (paths) to be provided by the Service and the rewrite rule bindings to those paths. This will be described in further detail in this section.
While the service.xml file is absolutely required, the rewrite.xml file in theory is optional (though it is highly unlikely that no rewrite rules are needed).
To add a new service, simply add a service.xml and rewrite.xml file in an appropriate directory (see Service Definition Directory Structure) in the module gateway-service-definitions to make the new service part of the Knox build.
Below is a sample of a very simple service.xml file, taking the same weather api example.
<service role="WEATHER" name="weather" version="0.1.0">
<routes>
<route path="/weather/**?**"/>
</routes>
</service>
<topology>
<gateway>
....
</gateway>
<service>
<role>WEATHER</role>
<name>weather</name>
<version>0.1.0</version>
<url>http://api.openweathermap.org/data</url>
</service>
....
</topology>
If only role is specified in the topology file (the only required element other than url) then the first service definition of that role found will be used with the highest version of that role and name. Similarly if only the version is omitted from the topology specification of the service, the service definition of the highest version will be used. It is therefore important to specify a version for a service if it is desired that a topology be locked down to a specific version of a service.
Below is an example of a snippet from the WebHDFS service definition
<route path="/webhdfs/v1/**?**">
<rewrite apply="WEBHDFS/webhdfs/inbound/namenode/file" to="request.url"/>
<rewrite apply="WEBHDFS/webhdfs/outbound/namenode/headers" to="response.headers"/>
</route>
This element can be used at the service level (i.e. as a child of the service tag) or at the route level. A dispatch specified at the route level takes precedence over a dispatch specified at the service level. By default the dispatch used is org.apache.hadoop.gateway.dispatch.DefaultDispatch.
The dispatch tag has four attributes that can be specified.
contributor-name : This attribute can be used to specify a deployment contributor to be invoked for a custom dispatch.
classname : This attribute can be used to specify a custom dispatch class.
ha-contributor-name : This attribute can be used to specify a deployment contributor to be invoked for custom HA dispatch functionality.
ha-classname : This attribute can be used to specify a custom dispatch class with HA functionality.
Only one of contributor-name or classname should be specified and one of ha-contributor-name or ha-classname should be specified.
If providing a custom dispatch, either a jar should be provided, see Class Path or a Maven Module should be created.
This element can contain one or more policy elements. The order of the policy elements is important as that will be the order of execution.
For example,
<service role="FOO" name="foo" version="1.0.0">
<policies>
<policy role="webappsec"/>
<policy role="authentication"/>
<policy role="rewrite"/>
<policy role="identity-assertion"/>
<policy role="authorization"/>
</policies>
<routes>
<route path="/foo/?**">
<rewrite apply="FOO/foo/inbound" to="request.url"/>
<policies>
<policy role="webappsec"/>
<policy role="federation"/>
<policy role="identity-assertion"/>
<policy role="authorization"/>
<policy role="rewrite"/>
</policies>
<dispatch contributor-name="http-client" />
</route>
</routes>
<dispatch contributor-name="custom-client" ha-contributor-name="ha-client"/>
</service>
The rewrite.xml file that accompanies the service.xml file follows the same rules as described in the section Rewrite Provider.
On installation of the Knox gateway, the following directory structure can be found under ${GATEWAY_HOME}/data. This is a mirror of the directories and files under the module gateway-service-definitions.
services
|______ service name
|______ version
|______service.xml
|______rewrite.xml
For example,
services
|______ webhdfs
|______ 2.4.0
|______service.xml
|______rewrite.xml
To test out a new service, you can just add the appropriate files (service.xml and rewrite.xml) in a directory under ${GATEWAY_HOME}/data/services. If you want to make the service contribution to the Knox build, they files need to go in the gateway-service-definitions module.
The runtime artifacts as well as the behavior does not change whether the service is plugged in via the deployment descriptors or through a service.xml file.
When writing a custom dispatch class, one often needs configuration or gateway services. A lightweight dependency injection system is used that can inject instances of classes or primitives available in the filter configuration’s init params or as a servlet context attribute.
Details of this can be found in the module gateway-util-configinjector and also an example use of it is in the class org.apache.hadoop.gateway.dispatch.DefaultDispatch. Look at the following method for example:
@Configure
protected void setReplayBufferSize(@Default("8") int size) {
replayBufferSize = size;
}
Apache Knox provides preauth federation authentication where
Knox supports two built-in validators for verifying incoming requests. In this section, we describe how to write a custom validator for this scenario. The provided validators include:
However, these built-in validation choices may not fulfill the internal requirments of some organization. Therefore, Knox supports (since 0.12) a pluggble framework where anyone can include a custom validator.
In essence, a user can add a custom validator by following these steps. The corresponding code examples are incorporated after that:
Validator Class (Step 2-4)
package com.company.knox.validator;
import org.apache.hadoop.gateway.preauth.filter.PreAuthValidationException;
import org.apache.hadoop.gateway.preauth.filter.PreAuthValidator;
import com.google.common.base.Strings;
import javax.servlet.FilterConfig;
import javax.servlet.http.HttpServletRequest;
public class CustomValidator extends PreAuthValidator {
//Any string constant value should work for these 3 variables
//This string will be used in 'services' file.
public static final String CUSTOM_VALIDATOR_NAME = "fooValidator";
//Optional: User may want to pass soemthign through HTTP header. (per client request)
public static final String CUSTOM_TOKEN_HEADER_NAME = "foo_claim";
/**
* @param httpRequest
* @param filterConfig
* @return
* @throws PreAuthValidationException
*/
@Override
public boolean validate(HttpServletRequest httpRequest, FilterConfig filterConfig) throws PreAuthValidationException {
String claimToken = httpRequest.getHeader(CUSTOM_TOKEN_HEADER_NAME);
if (!Strings.isNullOrEmpty(claimToken)) {
return checkCustomeToken(claimToken); //to be implemented
} else {
log.warn("Claim token was empty for header name '" + CUSTOM_TOKEN_HEADER_NAME + "'");
return false;
}
}
/**
* Define unique validator name
*
* @return
*/
@Override
public String getName() {
return CUSTOM_VALIDATOR_NAME;
}
}
META-INF/services contents (Step-5)
com.company.knox.validator.CustomValidator
POM file (Step-6)
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.knox</groupId>
<artifactId>gateway-test-utils</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.knox</groupId>
<artifactId>gateway-provider-security-preauth</artifactId>
<scope>provided</scope>
</dependency>
Deploy Custom Jar (Step-7-8)
Build the jar (e.g. customValidation.jar) using ‘mvn clean package’ cp customValidation.jar $GATEWAY_HOME/ext/
Topology Config (Step-9)
<provider>
<role>federation</role>
<name>HeaderPreAuth</name>
<enabled>true</enabled>
<param><name>preauth.validation.method</name>
<!--Same as CustomeValidator.CUSTOM_VALIDATOR_NAME ->
<value>fooValidator</value></param>
</provider>
public interface ProviderDeploymentContributor {
String getRole();
String getName();
void initializeContribution( DeploymentContext context );
void contributeProvider( DeploymentContext context, Provider provider );
void contributeFilter(
DeploymentContext context,
Provider provider,
Service service,
ResourceDescriptor resource,
List<FilterParamDescriptor> params );
void finalizeContribution( DeploymentContext context );
}
<project>
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.apache.hadoop</groupId>
<artifactId>gateway</artifactId>
<version>0.12.0-SNAPSHOT</version>
</parent>
<artifactId>gateway-provider-security-authn-sample</artifactId>
<name>gateway-provider-security-authn-sample</name>
<description>A simple sample authorization provider.</description>
<licenses>
<license>
<name>The Apache Software License, Version 2.0</name>
<url>https://www.apache.org/licenses/LICENSE-2.0.txt</url>
<distribution>repo</distribution>
</license>
</licenses>
<dependencies>
<dependency>
<groupId>${gateway-group}</groupId>
<artifactId>gateway-spi</artifactId>
</dependency>
</dependencies>
</project>
package org.apache.hadoop.gateway.deploy;
import ...
public interface DeploymentContext {
GatewayConfig getGatewayConfig();
Topology getTopology();
WebArchive getWebArchive();
WebAppDescriptor getWebAppDescriptor();
GatewayDescriptor getGatewayDescriptor();
void contributeFilter(
Service service,
ResourceDescriptor resource,
String role,
String name,
List<FilterParamDescriptor> params );
void addDescriptor( String name, Object descriptor );
<T> T getDescriptor( String name );
}
public class Topology {
public URI getUri() {...}
public void setUri( URI uri ) {...}
public String getName() {...}
public void setName( String name ) {...}
public long getTimestamp() {...}
public void setTimestamp( long timestamp ) {...}
public Collection<Service> getServices() {...}
public Service getService( String role, String name ) {...}
public void addService( Service service ) {...}
public Collection<Provider> getProviders() {...}
public Provider getProvider( String role, String name ) {...}
public void addProvider( Provider provider ) {...}
}
public interface GatewayDescriptor {
List<GatewayParamDescriptor> params();
GatewayParamDescriptor addParam();
GatewayParamDescriptor createParam();
void addParam( GatewayParamDescriptor param );
void addParams( List<GatewayParamDescriptor> params );
List<ResourceDescriptor> resources();
ResourceDescriptor addResource();
ResourceDescriptor createResource();
void addResource( ResourceDescriptor resource );
}
TODO - Describe the service registry and other global services.
gateway-provider-rewrite org.apache.hadoop.gateway.filter.rewrite.api.UrlRewriteRulesDescriptor
<rules>
<rule
dir="IN"
name="WEATHER/openweathermap/inbound/versioned/file"
pattern="*://*:*/**/weather/{version}?{**}">
<rewrite template="{$serviceUrl[WEATHER]}/{version}/weather?{**}"/>
</rule>
</rules>
<rules>
<filter name="WEBHBASE/webhbase/status/outbound">
<content type="*/json">
<apply path="$[LiveNodes][*][name]" rule="WEBHBASE/webhbase/address/outbound"/>
</content>
<content type="*/xml">
<apply path="/ClusterStatus/LiveNodes/Node/@name" rule="WEBHBASE/webhbase/address/outbound"/>
</content>
</filter>
</rules>
@Test
public void testDevGuideSample() throws Exception {
URI inputUri, outputUri;
Matcher<Void> matcher;
Matcher<Void>.Match match;
Template input, pattern, template;
inputUri = new URI( "http://sample-host:8443/gateway/topology/weather/2.5?q=Palo+Alto" );
input = Parser.parse( inputUri.toString() );
pattern = Parser.parse( "*://*:*/**/weather/{version}?{**}" );
template = Parser.parse( "http://api.openweathermap.org/data/{version}/weather?{**}" );
matcher = new Matcher<Void>();
matcher.add( pattern, null );
match = matcher.match( input );
outputUri = Expander.expand( template, match.getParams(), null );
assertThat(
outputUri.toString(),
is( "http://api.openweathermap.org/data/2.5/weather?q=Palo+Alto" ) );
}
@Test
public void testDevGuideSampleWithEvaluator() throws Exception {
URI inputUri, outputUri;
Matcher<Void> matcher;
Matcher<Void>.Match match;
Template input, pattern, template;
Evaluator evaluator;
inputUri = new URI( "http://sample-host:8443/gateway/topology/weather/2.5?q=Palo+Alto" );
input = Parser.parse( inputUri.toString() );
pattern = Parser.parse( "*://*:*/**/weather/{version}?{**}" );
template = Parser.parse( "{$serviceUrl[WEATHER]}/{version}/weather?{**}" );
matcher = new Matcher<Void>();
matcher.add( pattern, null );
match = matcher.match( input );
evaluator = new Evaluator() {
@Override
public List<String> evaluate( String function, List<String> parameters ) {
return Arrays.asList( "http://api.openweathermap.org/data" );
}
};
outputUri = Expander.expand( template, match.getParams(), evaluator );
assertThat(
outputUri.toString(),
is( "http://api.openweathermap.org/data/2.5/weather?q=Palo+Alto" ) );
}
TODO - Cover the supported content types. TODO - Provide a XML and JSON “properties” example where one NVP is modified based on value of another name.
<rules>
<filter name="WEBHBASE/webhbase/regions/outbound">
<content type="*/json">
<apply path="$[Region][*][location]" rule="WEBHBASE/webhbase/address/outbound"/>
</content>
<content type="*/xml">
<apply path="/TableInfo/Region/@location" rule="WEBHBASE/webhbase/address/outbound"/>
</content>
</filter>
</rules>
<gateway>
...
<resource>
<role>WEBHBASE</role>
<pattern>/hbase/*/regions?**</pattern>
...
<filter>
<role>rewrite</role>
<name>url-rewrite</name>
<class>org.apache.hadoop.gateway.filter.rewrite.api.UrlRewriteServletFilter</class>
<param>
<name>response.body</name>
<value>WEBHBASE/webhbase/regions/outbound</value>
</param>
</filter>
...
</resource>
...
</gateway>
HBaseDeploymentContributor
params = new ArrayList<FilterParamDescriptor>();
params.add( regionResource.createFilterParam().name( "response.body" ).value( "WEBHBASE/webhbase/regions/outbound" ) );
addRewriteFilter( context, service, regionResource, params );
TODO - Provide an lowercase function as an example.
<rules>
<functions>
<hostmap config="/WEB-INF/hostmap.txt"/>
</functions>
...
</rules>
TODO - Provide an lowercase step as an example.
<rules>
<rule dir="OUT" name="WEBHDFS/webhdfs/outbound/namenode/headers/location">
<match pattern="{scheme}://{host}:{port}/{path=**}?{**}"/>
<rewrite template="{gateway.url}/webhdfs/data/v1/{path=**}?{scheme}?host={$hostmap(host)}?{port}?{**}"/>
<encrypt-query/>
</rule>
</rules>
Adding a new identity assertion provider is as simple as extending the AbstractIdentityAsserterDeploymentContributor and the CommonIdentityAssertionFilter from the gateway-provider-identity-assertion-common module to initialize any specific configuration from filter init params and implement two methods:
To implement a simple toUpper or toLower identity assertion provider:
package org.apache.hadoop.gateway.identityasserter.caseshifter.filter;
import org.apache.hadoop.gateway.identityasserter.common.filter.AbstractIdentityAsserterDeploymentContributor;
public class CaseShifterIdentityAsserterDeploymentContributor extends AbstractIdentityAsserterDeploymentContributor {
@Override
public String getName() {
return "CaseShifter";
}
protected String getFilterClassname() {
return CaseShifterIdentityAssertionFilter.class.getName();
}
}
We merely need to provide the provider name for use in the topology and the filter classname for the contributor to add to the filter chain.
For the identity assertion filter itself it is just a matter of extension and the implementation of the two methods described earlier:
package org.apache.hadoop.gateway.identityasserter.caseshifter.filter;
import javax.security.auth.Subject;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import org.apache.hadoop.gateway.identityasserter.common.filter.CommonIdentityAssertionFilter;
public class CaseShifterIdentityAssertionFilter extends CommonIdentityAssertionFilter {
private boolean toUpper = false;
@Override
public void init(FilterConfig filterConfig) throws ServletException {
String upper = filterConfig.getInitParameter("caseshift.upper");
if ("true".equals(upper)) {
toUpper = true;
}
}
@Override
public String[] mapGroupPrincipals(String mappedPrincipalName, Subject subject) {
return null;
}
@Override
public String mapUserPrincipal(String principalName) {
if (toUpper) {
principalName = principalName.toUpperCase();
}
else {
principalName = principalName.toLowerCase();
}
return principalName;
}
}
Note that the above:
That is the extent of what is needed to implement a new identity assertion provider module.
TODO
KnoxSSO provides an abstraction for integrating any number of authentication systems and SSO solutions and enables participating web applications to scale to those solutions more easily. Without the token exchange capabilities offered by KnoxSSO each component UI would need to integrate with each desired solution on its own.
This document examines the way to integrate with Knox SSO in the form of a Servlet Filter. This approach should be easily extrapolated into other frameworks - ie. Spring Security.
The following is a generic sequence diagram for SAML integration through KnoxSSO.
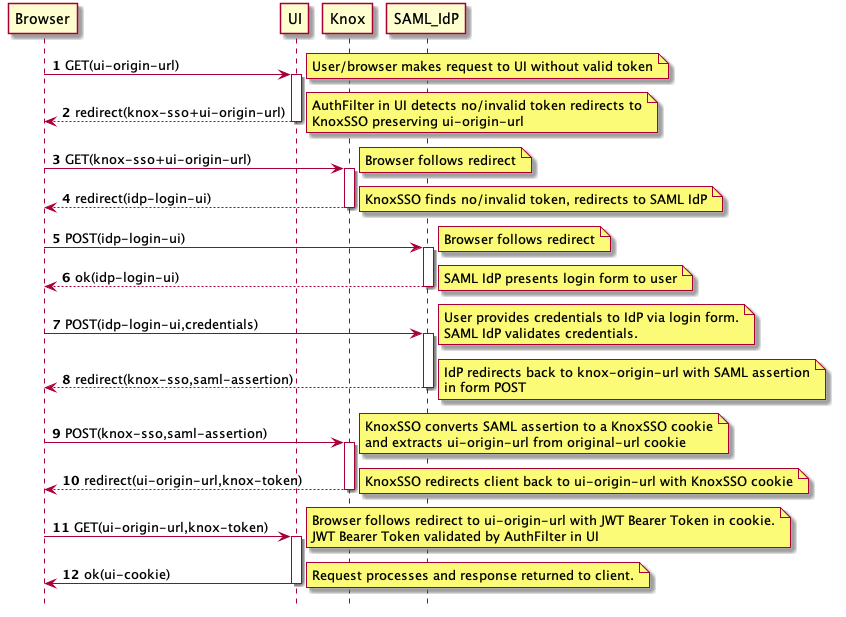
In order to enable KnoxSSO, we need to configure the IdP topology. The following is an example of this topology that is configured to use HTTP Basic Auth against the Knox Demo LDAP server. This is the lowest barrier of entry for your development environment that actually authenticates against a real user store. What’s great is if you work against the IdP with Basic Auth then you will work with SAML or anything else as well.
<?xml version="1.0" encoding="utf-8"?>
<topology>
<gateway>
<provider>
<role>authentication</role>
<name>ShiroProvider</name>
<enabled>true</enabled>
<param>
<name>sessionTimeout</name>
<value>30</value>
</param>
<param>
<name>main.ldapRealm</name>
<value>org.apache.hadoop.gateway.shirorealm.KnoxLdapRealm</value>
</param>
<param>
<name>main.ldapContextFactory</name>
<value>org.apache.hadoop.gateway.shirorealm.KnoxLdapContextFactory</value>
</param>
<param>
<name>main.ldapRealm.contextFactory</name>
<value>$ldapContextFactory</value>
</param>
<param>
<name>main.ldapRealm.userDnTemplate</name>
<value>uid={0},ou=people,dc=hadoop,dc=apache,dc=org</value>
</param>
<param>
<name>main.ldapRealm.contextFactory.url</name>
<value>ldap://localhost:33389</value>
</param>
<param>
<name>main.ldapRealm.contextFactory.authenticationMechanism</name>
<value>simple</value>
</param>
<param>
<name>urls./**</name>
<value>authcBasic</value>
</param>
</provider>
<provider>
<role>identity-assertion</role>
<name>Default</name>
<enabled>true</enabled>
</provider>
</gateway>
<service>
<role>KNOXSSO</role>
<param>
<name>knoxsso.cookie.secure.only</name>
<value>true</value>
</param>
<param>
<name>knoxsso.token.ttl</name>
<value>100000</value>
</param>
</service>
</topology>
Just as with any Knox service, the KNOXSSO service is protected by the gateway providers defined above it. In this case, the ShiroProvider is taking care of HTTP Basic Auth against LDAP for us. Once the user authenticates the request processing continues to the KNOXSSO service that will create the required cookie and do the necessary redirects.
The authenticate/federation provider can be swapped out to fit your deployment environment.
In order to see the end to end story and use it as an example in your development, you can configure one of the cluster topologies to use the SSOCookieProvider instead of the out of the box ShiroProvider. The following is an example sandbox.xml topology that is configured for using KnoxSSO to protect access to the Hadoop REST APIs.
<?xml version="1.0" encoding="utf-8"?>
<topology>
<gateway>
<provider>
<role>federation</role>
<name>SSOCookieProvider</name>
<enabled>true</enabled>
<param>
<name>sso.authentication.provider.url</name>
<value>https://localhost:9443/gateway/idp/api/v1/websso</value>
</param>
</provider>
<provider>
<role>identity-assertion</role>
<name>Default</name>
<enabled>true</enabled>
</provider>
</gateway>
<service>
<role>NAMENODE</role>
<url>hdfs://localhost:8020</url>
</service>
<service>
<role>JOBTRACKER</role>
<url>rpc://localhost:8050</url>
</service>
<service>
<role>WEBHDFS</role>
<url>http://localhost:50070/webhdfs</url>
</service>
<service>
<role>WEBHCAT</role>
<url>http://localhost:50111/templeton</url>
</service>
<service>
<role>OOZIE</role>
<url>http://localhost:11000/oozie</url>
</service>
<service>
<role>WEBHBASE</role>
<url>http://localhost:60080</url>
</service>
<service>
<role>HIVE</role>
<url>http://localhost:10001/cliservice</url>
</service>
<service>
<role>RESOURCEMANAGER</role>
<url>http://localhost:8088/ws</url>
</service>
</topology>
As you can see above, the only thing being configured is the SSO provider URL. Since Knox is the issuer of the cookie and token, we don’t need to configure the public key since we have programmatic access to the actual keystore for use at verification time.
We should now be able to walk through the SSO Flow at the command line with curl to see everything that happens.
First, issue a request to WEBHDFS through knox.
bash-3.2$ curl -iku guest:guest-password https://localhost:8443/gateway/sandbox/webhdfs/v1/tmp?op+LISTSTATUS
HTTP/1.1 302 Found
Location: https://localhost:8443/gateway/idp/api/v1/websso?originalUrl=https://localhost:8443/gateway/sandbox/webhdfs/v1/tmp?op+LISTSTATUS
Content-Length: 0
Server: Jetty(8.1.14.v20131031)
Note the redirect to the knoxsso endpoint and the loginUrl with the originalUrl request parameter. We need to see that come from your integration as well.
Let’s manually follow that redirect with curl now:
bash-3.2$ curl -iku guest:guest-password "https://localhost:8443/gateway/idp/api/v1/websso?originalUrl=https://localhost:9443/gateway/sandbox/webhdfs/v1/tmp?op=LISTSTATUS"
HTTP/1.1 307 Temporary Redirect
Set-Cookie: JSESSIONID=mlkda4crv7z01jd0q0668nsxp;Path=/gateway/idp;Secure;HttpOnly
Set-Cookie: hadoop-jwt=eyJhbGciOiJSUzI1NiJ9.eyJleHAiOjE0NDM1ODUzNzEsInN1YiI6Imd1ZXN0IiwiYXVkIjoiSFNTTyIsImlzcyI6IkhTU08ifQ.RpA84Qdr6RxEZjg21PyVCk0G1kogvkuJI2bo302bpwbvmc-i01gCwKNeoGYzUW27MBXf6a40vylHVR3aZuuBUxsJW3aa_ltrx0R5ztKKnTWeJedOqvFKSrVlBzJJ90PzmDKCqJxA7JUhyo800_lDHLTcDWOiY-ueWYV2RMlCO0w;Path=/;Domain=localhost;Secure;HttpOnly
Expires: Thu, 01 Jan 1970 00:00:00 GMT
Location: https://localhost:8443/gateway/sandbox/webhdfs/v1/tmp?op=LISTSTATUS
Content-Length: 0
Server: Jetty(8.1.14.v20131031)
Note the redirect back to the original URL in the Location header and the Set-Cookie for the hadoop-jwt cookie. This is what the SSOCookieProvider in sandbox (and ultimately in your integration) will be looking for.
Finally, we should be able to take the above cookie and pass it to the original url as indicated in the Location header for our originally requested resource:
bash-3.2$ curl -ikH "Cookie: hadoop-jwt=eyJhbGciOiJSUzI1NiJ9.eyJleHAiOjE0NDM1ODY2OTIsInN1YiI6Imd1ZXN0IiwiYXVkIjoiSFNTTyIsImlzcyI6IkhTU08ifQ.Os5HEfVBYiOIVNLRIvpYyjeLgAIMbBGXHBWMVRAEdiYcNlJRcbJJ5aSUl1aciNs1zd_SHijfB9gOdwnlvQ_0BCeGHlJBzHGyxeypIoGj9aOwEf36h-HVgqzGlBLYUk40gWAQk3aRehpIrHZT2hHm8Pu8W-zJCAwUd8HR3y6LF3M;Path=/;Domain=localhost;Secure;HttpOnly" https://localhost:9443/gateway/sandbox/webhdfs/v1/tmp?op=LISTSTATUS
TODO: cluster was down and needs to be recreated :/
At this point, we can use a web browser instead of the command line and see how the browser will challenge the user for Basic Auth Credentials and then manage the cookies such that the SSO and token exchange aspects of the flow are hidden from the user.
Simply, try to invoke the same webhdfs API from the browser URL bar.
https://localhost:8443/gateway/sandbox/webhdfs/v1/tmp?op=LISTSTATUS
Based on our understanding of the flow it should behave like:
We have added a federation provider to Knox for accepting KnoxSSO cookies for REST APIs. This provides us with a couple benefits: KnoxSSO support for REST APIs for XmlHttpRequests from JavaScript (basic CORS functionality is also included). This is still rather basic and considered beta code. A model and real world usecase for others to base their integrations on
In addition, https://issues.apache.org/jira/browse/HADOOP-11717 added support for the Hadoop UIs to the hadoop-auth module and it can be used as another example.
We will examine the new SSOCookieFederationFilter in Knox here.
package org.apache.hadoop.gateway.provider.federation.jwt.filter;
import java.io.IOException;
import java.security.Principal;
import java.security.PrivilegedActionException;
import java.security.PrivilegedExceptionAction;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import javax.security.auth.Subject;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.hadoop.gateway.i18n.messages.MessagesFactory;
import org.apache.hadoop.gateway.provider.federation.jwt.JWTMessages;
import org.apache.hadoop.gateway.security.PrimaryPrincipal;
import org.apache.hadoop.gateway.services.GatewayServices;
import org.apache.hadoop.gateway.services.security.token.JWTokenAuthority;
import org.apache.hadoop.gateway.services.security.token.TokenServiceException;
import org.apache.hadoop.gateway.services.security.token.impl.JWTToken;
public class SSOCookieFederationFilter implements Filter {
private static JWTMessages log = MessagesFactory.get( JWTMessages.class );
private static final String ORIGINAL_URL_QUERY_PARAM = "originalUrl=";
private static final String SSO_COOKIE_NAME = "sso.cookie.name";
private static final String SSO_EXPECTED_AUDIENCES = "sso.expected.audiences";
private static final String SSO_AUTHENTICATION_PROVIDER_URL = "sso.authentication.provider.url";
private static final String DEFAULT_SSO_COOKIE_NAME = "hadoop-jwt";
The above represent the configurable aspects of the integration
private JWTokenAuthority authority = null;
private String cookieName = null;
private List<String> audiences = null;
private String authenticationProviderUrl = null;
@Override
public void init( FilterConfig filterConfig ) throws ServletException {
GatewayServices services = (GatewayServices) filterConfig.getServletContext().getAttribute(GatewayServices.GATEWAY_SERVICES_ATTRIBUTE);
authority = (JWTokenAuthority)services.getService(GatewayServices.TOKEN_SERVICE);
The above is a Knox specific internal service that we use to issue and verify JWT tokens. This will be covered separately and you will need to be implement something similar in your filter implementation.
// configured cookieName
cookieName = filterConfig.getInitParameter(SSO_COOKIE_NAME);
if (cookieName == null) {
cookieName = DEFAULT_SSO_COOKIE_NAME;
}
The configurable cookie name is something that can be used to change a cookie name to fit your deployment environment. The default name is hadoop-jwt which is also the default in the Hadoop implementation. This name must match the name being used by the KnoxSSO endpoint when setting the cookie.
// expected audiences or null
String expectedAudiences = filterConfig.getInitParameter(SSO_EXPECTED_AUDIENCES);
if (expectedAudiences != null) {
audiences = parseExpectedAudiences(expectedAudiences);
}
Audiences are configured as a comma separated list of audience strings. Names of intended recipients or intents. The semantics that we are using for this processing is that - if not configured than any (or none) audience is accepted. If there are audiences configured then as long as one of the expected ones is found in the set of claims in the token it is accepted.
// url to SSO authentication provider
authenticationProviderUrl = filterConfig.getInitParameter(SSO_AUTHENTICATION_PROVIDER_URL);
if (authenticationProviderUrl == null) {
log.missingAuthenticationProviderUrlConfiguration();
}
}
This is the URL to the KnoxSSO endpoint. It is required and SSO/token exchange will not work without this set correctly.
/**
* @param expectedAudiences
* @return
*/
private List<String> parseExpectedAudiences(String expectedAudiences) {
ArrayList<String> audList = null;
// setup the list of valid audiences for token validation
if (expectedAudiences != null) {
// parse into the list
String[] audArray = expectedAudiences.split(",");
audList = new ArrayList<String>();
for (String a : audArray) {
audList.add(a);
}
}
return audList;
}
The above method parses the comma separated list of expected audiences and makes it available for interrogation during token validation.
public void destroy() {
}
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
String wireToken = null;
HttpServletRequest req = (HttpServletRequest) request;
String loginURL = constructLoginURL(req);
wireToken = getJWTFromCookie(req);
if (wireToken == null) {
if (req.getMethod().equals("OPTIONS")) {
// CORS preflight requests to determine allowed origins and related config
// must be able to continue without being redirected
Subject sub = new Subject();
sub.getPrincipals().add(new PrimaryPrincipal("anonymous"));
continueWithEstablishedSecurityContext(sub, req, (HttpServletResponse) response, chain);
}
log.sendRedirectToLoginURL(loginURL);
((HttpServletResponse) response).sendRedirect(loginURL);
}
else {
JWTToken token = new JWTToken(wireToken);
boolean verified = false;
try {
verified = authority.verifyToken(token);
if (verified) {
Date expires = token.getExpiresDate();
if (expires == null || new Date().before(expires)) {
boolean audValid = validateAudiences(token);
if (audValid) {
Subject subject = createSubjectFromToken(token);
continueWithEstablishedSecurityContext(subject, (HttpServletRequest)request, (HttpServletResponse)response, chain);
}
else {
log.failedToValidateAudience();
((HttpServletResponse) response).sendRedirect(loginURL);
}
}
else {
log.tokenHasExpired();
((HttpServletResponse) response).sendRedirect(loginURL);
}
}
else {
log.failedToVerifyTokenSignature();
((HttpServletResponse) response).sendRedirect(loginURL);
}
} catch (TokenServiceException e) {
log.unableToVerifyToken(e);
((HttpServletResponse) response).sendRedirect(loginURL);
}
}
}
The doFilter method above is where all the real work is done. We look for a cookie by the configured name. If it isn’t there then we redirect to the configured SSO provider URL in order to acquire one. That is unless it is an OPTIONS request which may be a preflight CORS request. You shouldn’t need to worry about this aspect. It is really a REST API concern not a web app UI one.
Once we get a cookie, the underlying JWT token is extracted and returned as the wireToken from which we create a Knox specific JWTToken. This abstraction is around the use of the nimbus JWT library which you can use directly. We will cover those details separately.
We then ask the token authority component to verify the token. This involves signature validation of the signed token. In order to verify the signature of the token you will need to have the public key of the Knox SSO server configured and provided to the nimbus library through its API at verification time. NOTE: This is a good place to look at the Hadoop implementation as an example.
Once we know the token is signed by a trusted party we then validate whether it is expired and that it has an expected (or no) audience claims.
Finally, when we have a valid token, we create a Java Subject from it and continue the request through the filterChain as the authenticated user.
/**
* Encapsulate the acquisition of the JWT token from HTTP cookies within the
* request.
*
* @param req servlet request to get the JWT token from
* @return serialized JWT token
*/
protected String getJWTFromCookie(HttpServletRequest req) {
String serializedJWT = null;
Cookie[] cookies = req.getCookies();
if (cookies != null) {
for (Cookie cookie : cookies) {
if (cookieName.equals(cookie.getName())) {
log.cookieHasBeenFound(cookieName);
serializedJWT = cookie.getValue();
break;
}
}
}
return serializedJWT;
}
The above method extracts the serialized token from the cookie and returns it as the wireToken.
/**
* Create the URL to be used for authentication of the user in the absence of
* a JWT token within the incoming request.
*
* @param request for getting the original request URL
* @return url to use as login url for redirect
*/
protected String constructLoginURL(HttpServletRequest request) {
String delimiter = "?";
if (authenticationProviderUrl.contains("?")) {
delimiter = "&";
}
String loginURL = authenticationProviderUrl + delimiter
+ ORIGINAL_URL_QUERY_PARAM
+ request.getRequestURL().toString()+ getOriginalQueryString(request);
return loginURL;
}
private String getOriginalQueryString(HttpServletRequest request) {
String originalQueryString = request.getQueryString();
return (originalQueryString == null) ? "" : "?" + originalQueryString;
}
The above method creates the full URL to be used in redirecting to the KnoxSSO endpoint. It includes the SSO provider URL as well as the original request URL so that we can redirect back to it after authentication and token exchange.
/**
* Validate whether any of the accepted audience claims is present in the
* issued token claims list for audience. Override this method in subclasses
* in order to customize the audience validation behavior.
*
* @param jwtToken
* the JWT token where the allowed audiences will be found
* @return true if an expected audience is present, otherwise false
*/
protected boolean validateAudiences(JWTToken jwtToken) {
boolean valid = false;
String[] tokenAudienceList = jwtToken.getAudienceClaims();
// if there were no expected audiences configured then just
// consider any audience acceptable
if (audiences == null) {
valid = true;
} else {
// if any of the configured audiences is found then consider it
// acceptable
for (String aud : tokenAudienceList) {
if (audiences.contains(aud)) {
//log.debug("JWT token audience has been successfully validated");
log.jwtAudienceValidated();
valid = true;
break;
}
}
}
return valid;
}
The above method implements the audience claim semantics explained earlier.
private void continueWithEstablishedSecurityContext(Subject subject, final HttpServletRequest request, final HttpServletResponse response, final FilterChain chain) throws IOException, ServletException {
try {
Subject.doAs(
subject,
new PrivilegedExceptionAction<Object>() {
@Override
public Object run() throws Exception {
chain.doFilter(request, response);
return null;
}
}
);
}
catch (PrivilegedActionException e) {
Throwable t = e.getCause();
if (t instanceof IOException) {
throw (IOException) t;
}
else if (t instanceof ServletException) {
throw (ServletException) t;
}
else {
throw new ServletException(t);
}
}
}
This method continues the filter chain processing upon successful validation of the token. This would need to be replaced with your environment’s equivalent of continuing the request or login to the app as the authenticated user.
private Subject createSubjectFromToken(JWTToken token) {
final String principal = token.getSubject();
@SuppressWarnings("rawtypes")
HashSet emptySet = new HashSet();
Set<Principal> principals = new HashSet<Principal>();
Principal p = new PrimaryPrincipal(principal);
principals.add(p);
javax.security.auth.Subject subject = new javax.security.auth.Subject(true, principals, emptySet, emptySet);
return subject;
}
This method takes a JWTToken and creates a Java Subject with the principals expected by the rest of the Knox processing. This would need to be implemented in a way appropriate for your operating environment as well. For instance, the Hadoop handler implementation returns a Hadoop AuthenticationToken to the calling filter which in turn ends up in the Hadoop auth cookie.
}
The following is the method from the Hadoop handler implementation that validates the signature.
/**
* Verify the signature of the JWT token in this method. This method depends on the * public key that was established during init based upon the provisioned public key. * Override this method in subclasses in order to customize the signature verification behavior.
* @param jwtToken the token that contains the signature to be validated
* @return valid true if signature verifies successfully; false otherwise
*/
protected boolean validateSignature(SignedJWT jwtToken){
boolean valid=false;
if (JWSObject.State.SIGNED == jwtToken.getState()) {
LOG.debug("JWT token is in a SIGNED state");
if (jwtToken.getSignature() != null) {
LOG.debug("JWT token signature is not null");
try {
JWSVerifier verifier=new RSASSAVerifier(publicKey);
if (jwtToken.verify(verifier)) {
valid=true;
LOG.debug("JWT token has been successfully verified");
}
else {
LOG.warn("JWT signature verification failed.");
}
}
catch (JOSEException je) {
LOG.warn("Error while validating signature",je);
}
}
}
return valid;
}
Hadoop Configuration Example The following is like the configuration in the Hadoop handler implementation.
OBSOLETE but in the proper spirit of HADOOP-11717 ( HADOOP-11717 - Add Redirecting WebSSO behavior with JWT Token in Hadoop Auth RESOLVED )
<property>
<name>hadoop.http.authentication.type</name>
<value>org.apache.hadoop/security.authentication/server.JWTRedirectAuthenticationHandler</value>
</property>
This is the handler classname in Hadoop auth for JWT token (KnoxSSO) support.
<property>
<name>hadoop.http.authentication.authentication.provider.url</name>
<value>http://c6401.ambari.apache.org:8888/knoxsso</value>
</property>
The above property is the SSO provider URL that points to the knoxsso endpoint.
<property>
<name>hadoop.http.authentication.public.key.pem</name>
<value>MIICVjCCAb+gAwIBAgIJAPPvOtuTxFeiMA0GCSqGSIb3DQEBBQUAMG0xCzAJBgNV
BAYTAlVTMQ0wCwYDVQQIEwRUZXN0MQ0wCwYDVQQHEwRUZXN0MQ8wDQYDVQQKEwZI
YWRvb3AxDTALBgNVBAsTBFRlc3QxIDAeBgNVBAMTF2M2NDAxLmFtYmFyaS5hcGFj
aGUub3JnMB4XDTE1MDcxNjE4NDcyM1oXDTE2MDcxNTE4NDcyM1owbTELMAkGA1UE
BhMCVVMxDTALBgNVBAgTBFRlc3QxDTALBgNVBAcTBFRlc3QxDzANBgNVBAoTBkhh
ZG9vcDENMAsGA1UECxMEVGVzdDEgMB4GA1UEAxMXYzY0MDEuYW1iYXJpLmFwYWNo
ZS5vcmcwgZ8wDQYJKoZIhvcNAQEBBQADgY0AMIGJAoGBAMFs/rymbiNvg8lDhsdA
qvh5uHP6iMtfv9IYpDleShjkS1C+IqId6bwGIEO8yhIS5BnfUR/fcnHi2ZNrXX7x
QUtQe7M9tDIKu48w//InnZ6VpAqjGShWxcSzR6UB/YoGe5ytHS6MrXaormfBg3VW
tDoy2MS83W8pweS6p5JnK7S5AgMBAAEwDQYJKoZIhvcNAQEFBQADgYEANyVg6EzE
2q84gq7wQfLt9t047nYFkxcRfzhNVL3LB8p6IkM4RUrzWq4kLA+z+bpY2OdpkTOe
wUpEdVKzOQd4V7vRxpdANxtbG/XXrJAAcY/S+eMy1eDK73cmaVPnxPUGWmMnQXUi
TLab+w8tBQhNbq6BOQ42aOrLxA8k/M4cV1A=</value>
</property>
The above property holds the KnoxSSO server’s public key for signature verification. Adding it directly to the config like this is convenient and is easily done through Ambari to existing config files that take custom properties. Config is generally protected as root access only as well - so it is a pretty good solution.
In order to turn the pem encoded config item into a public key the hadoop handler implementation does the following in the init() method.
if (publicKey == null) {
String pemPublicKey = config.getProperty(PUBLIC_KEY_PEM);
if (pemPublicKey == null) {
throw new ServletException(
"Public key for signature validation must be provisioned.");
}
publicKey = CertificateUtil.parseRSAPublicKey(pemPublicKey);
}
and the CertificateUtil class is below:
package org.apache.hadoop.security.authentication.util;
import java.io.ByteArrayInputStream;
import java.io.UnsupportedEncodingException;
import java.security.PublicKey;
import java.security.cert.CertificateException;
import java.security.cert.CertificateFactory;
import java.security.cert.X509Certificate;
import java.security.interfaces.RSAPublicKey;
import javax.servlet.ServletException;
public class CertificateUtil {
private static final String PEM_HEADER = "-----BEGIN CERTIFICATE-----\n";
private static final String PEM_FOOTER = "\n-----END CERTIFICATE-----";
/**
* Gets an RSAPublicKey from the provided PEM encoding.
*
* @param pem
* - the pem encoding from config without the header and footer
* @return RSAPublicKey the RSA public key
* @throws ServletException thrown if a processing error occurred
*/
public static RSAPublicKey parseRSAPublicKey(String pem) throws ServletException {
String fullPem = PEM_HEADER + pem + PEM_FOOTER;
PublicKey key = null;
try {
CertificateFactory fact = CertificateFactory.getInstance("X.509");
ByteArrayInputStream is = new ByteArrayInputStream(
fullPem.getBytes("UTF8"));
X509Certificate cer = (X509Certificate) fact.generateCertificate(is);
key = cer.getPublicKey();
} catch (CertificateException ce) {
String message = null;
if (pem.startsWith(PEM_HEADER)) {
message = "CertificateException - be sure not to include PEM header "
+ "and footer in the PEM configuration element.";
} else {
message = "CertificateException - PEM may be corrupt";
}
throw new ServletException(message, ce);
} catch (UnsupportedEncodingException uee) {
throw new ServletException(uee);
}
return (RSAPublicKey) key;
}
}
public class AuditingSample {
private static Auditor AUDITOR = AuditServiceFactory.getAuditService().getAuditor(
"sample-channel", "sample-service", "sample-component" );
public void sampleMethod() {
...
AUDITOR.audit( Action.AUTHORIZATION, sourceUrl, ResourceType.URI, ActionOutcome.SUCCESS );
...
}
}
@Messages( logger = "org.apache.project.module" )
public interface CustomMessages {
@Message( level = MessageLevel.FATAL, text = "Failed to parse command line: {0}" )
void failedToParseCommandLine( @StackTrace( level = MessageLevel.DEBUG ) ParseException e );
}
public class CustomLoggingSample {
private static GatewayMessages MSG = MessagesFactory.get( GatewayMessages.class );
public void sampleMethod() {
...
MSG.failedToParseCommandLine( e );
...
}
}
@Resources
public interface CustomResources {
@Resource( text = "Apache Hadoop Gateway {0} ({1})" )
String gatewayVersionMessage( String version, String hash );
}
public class CustomResourceSample {
private static GatewayResources RES = ResourcesFactory.get( GatewayResources.class );
public void sampleMethod() {
...
String s = RES.gatewayVersionMessage( "0.0.0", "XXXXXXX" ) );
...
}
}
The Admin UI is a work in progress. It has started with viewpoint of being a simple web interface for Admin API functions but will hopefully grow into being able to also provide visibility into the gateway in terms of logs and metrics.
The Admin UI application follows the architecture of a hosted application in Knox. To that end it needs to be packaged up in the gateway-applications module in the source tree so that in the installation it can wind up here
<GATEWAY_HOME>/data/applications/admin-ui
However since the application is built using angular and various node modules the source tree is not something we want to place into the gateway-applications module. Instead we will place the production ‘binaries’ in gateway-applications and have the source in a module called ‘gateway-admin-ui’.
To work with the angular application you need to install some prerequisite tools.
The main tool needed is the angular cli and while installing that you will get its dependencies which should fulfill any other requirements Prerequisites
Also be aware that there is a package.json file in the module, so to get all dependencies in the module simply type
npm install
At the time of writing this the gateway-admin-ui module is not part of the maven build.
Any changes in the module must be promoted to the gateway-application modules. The following ant commands can be used to make this easy.
ant build-admin-ui
This uses the ng cli to build the source.
ant promote-admin-ui
This copies over the minified files for the application to the gateway-applications module.
The Admin UI is deployed to a fixed topology. The topology file can be found under
<GATEWAY_HOME>/conf/topologies/manager.xml
The topology hosts an instance of the Admin API for the UI to use. The reason for this is that the existing Admin API needs to have a different security model from that used by the Admin UI. The key components of this topology are:
<provider>
<role>webappsec</role>
<name>WebAppSec</name>
<enabled>true</enabled>
<param><name>csrf.enabled</name><value>true</value></param>
<param><name>csrf.customHeader</name><value>X-XSRF-Header</value></param>
<param><name>csrf.methodsToIgnore</name><value>GET,OPTIONS,HEAD</value></param>
<param><name>xframe-options.enabled</name><value>true</value></param>
</provider>
and
<application>
<role>admin-ui</role>
</application>
Apache Knox, Apache Knox Gateway, Apache, the Apache feather logo and the Apache Knox Gateway project logos are trademarks of The Apache Software Foundation. All other marks mentioned may be trademarks or registered trademarks of their respective owners.
Apache Knox uses the standard Apache license.
Apache Knox uses the standard Apache privacy policy.
Information about your use of this website is collected using server access logs and a tracking cookie. The collected information consists of the following:
Part of this information is gathered using a tracking cookie set by the Google Analytics service. Google’s policy for the use of this information is described in their privacy policy. See your browser’s documentation for instructions on how to disable the cookie if you prefer not to share this data with Google.
We use the gathered information to help us make our site more useful to visitors and to better understand how and when our site is used. We do not track or collect personally identifiable information or associate gathered data with any personally identifying information from other sources.
By using this website, you consent to the collection of this data in the manner and for the purpose described above.